作者|Authors: Julia Wiesinger, Patrick Marlow and Vladimir Vuskovic
作者|Authors: Julia Wiesinger, Patrick Marlow and Vladimir Vuskovic摘要
-
Agent通过利用工具访问实时信息、建议现实世界中的行动并自主规划和执行复杂任务来扩展语言模型的能力。Agent可以利用一个或多个语言模型,决定何时以及如何在状态之间进行过渡,并使用外部工具完成任何数量的复杂任务,这些任务对于该模型来说可能难以完成甚至不可能完成。 -
委托人的操作核心是协调层,这是一种认知架构,它结构化推理、规划和决策,并指导其行动。各种推理技术如ReAct、Chain-of-Thought 和Tree-of-Thought 提供了协调层获取信息、进行内部推理并生成有根据的决定或响应的框架。 -
工具,例如扩展、函数和数据存储,是Agent与外部世界之间的钥匙,允许它们与其他系统交互并访问超出其训练数据的知识。扩展为Agent和外部API提供桥梁,使Agent能够执行API调用并检索实时信息。函数通过分工提供了更细致的控制,让开发人员可以生成可以在客户端执行的功能参数。数据存储为Agent提供对结构化或非结构化数据的访问权限,从而实现基于数据的应用程序。
什么是Agent?
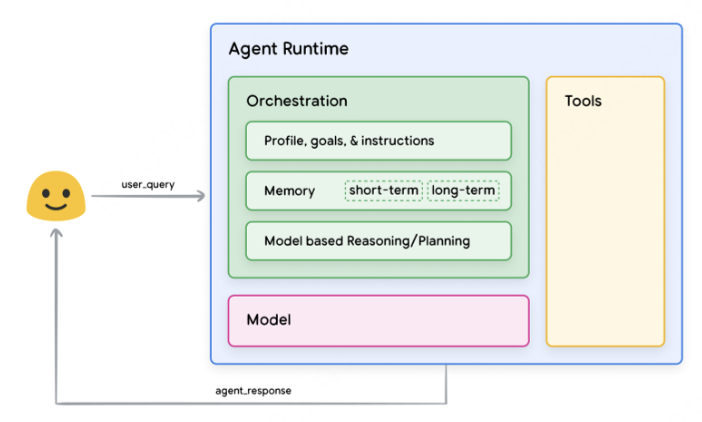
模型(Model)
工具(Tools)
编排层(Orchestration layer)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Agent如何运行?
-
他们收集信息,比如顾客的订单和冰箱里的配料。 -
他们根据刚刚收集到的信息,进行一些内部推理,以确定可以创建哪些菜肴和风味轮廓。 -
他们采取行动来制作这道菜:切蔬菜,混合香料,煎肉。
-
ReAct 是一个提示工程框架,为语言模型提供了一种推理和对用户查询采取行动的思维过程策略。ReAct 提示已显示出优于几个最先进的基准,并提高了人类与 LLM 的互操作性和信任度。 -
Chain-of-Thought(CoT),一种通过中间步骤实现推理能力的提示工程框架。CoT包括各种子技术,如自我一致性、主动提示和多模态CoT,每种技术都有其优点和缺点,具体取决于特定的应用程序。 -
Tree-of-thoughts(ToT),,一种适用于探索或战略前瞻任务的提示工程框架。它超越了链式思维提示,并允许模型探索各种思维链条,这些思维链条作为语言模型解决一般问题的中间步骤。
-
-
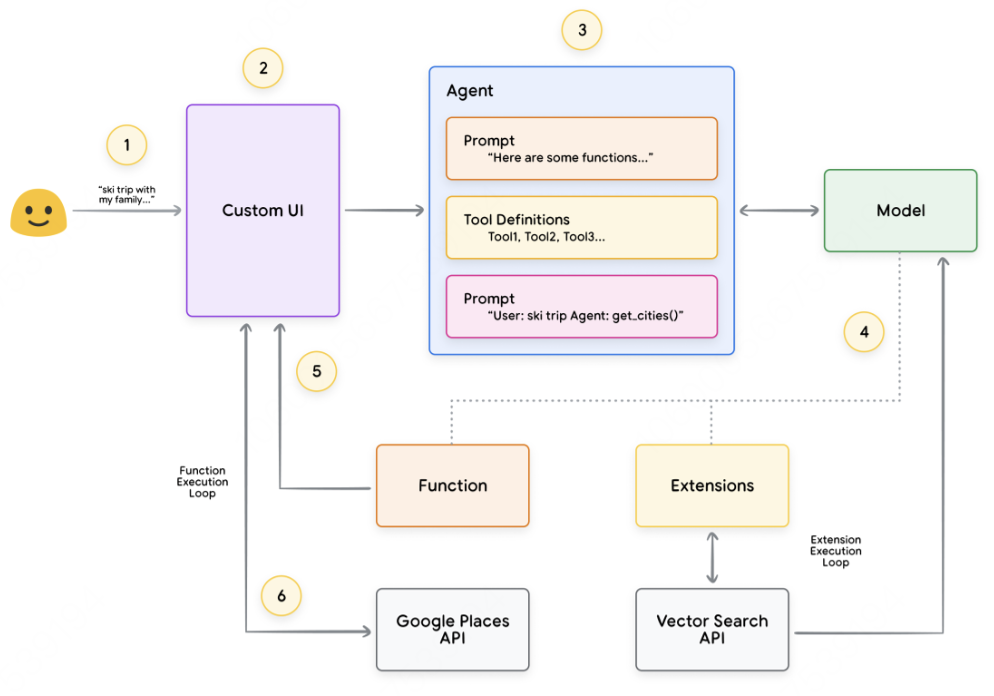
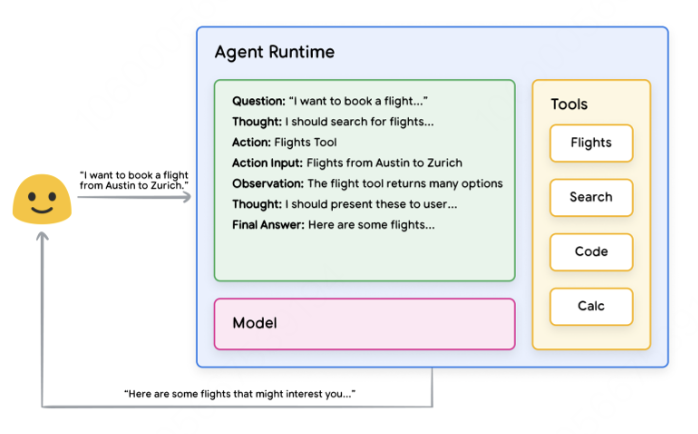
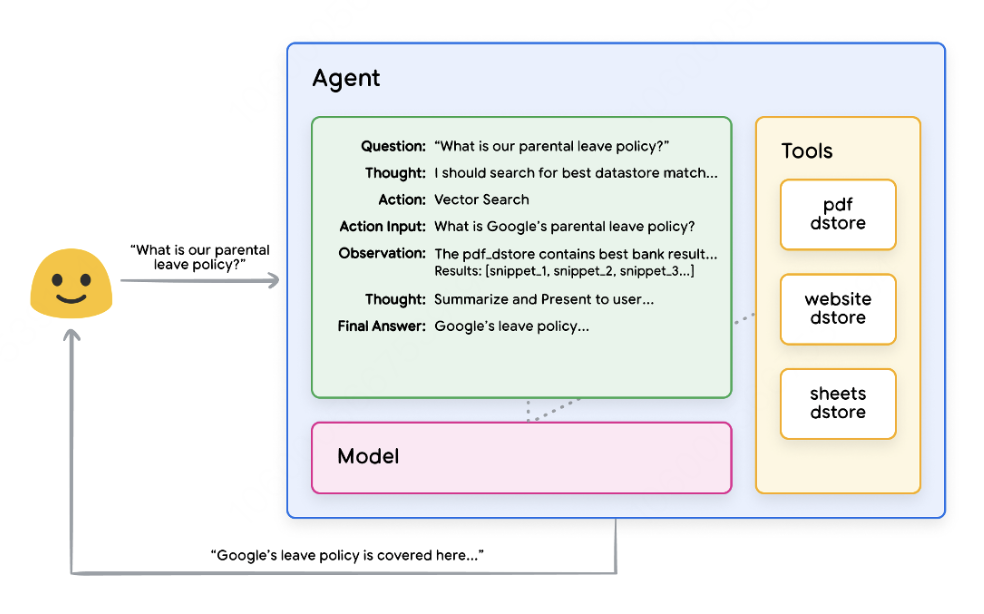
用户向Agent发送查询 -
Agent开始启动 ReAct -
Agent向模型提供提示,要求它生成下一个ReAct步骤及其相应的输出: -
这个想法/行动/输入/观察可以重复N次,根据需要
-
-
-
-
问题:用户查询输入的问题,提供提示 -
思想:模特关于下一步应该做什么的想法 -
行动:模型对下一步采取什么行动的决定 -
动作输入:模型决定向工具提供什么输入(如果有) -
观察:操作的结果/操作输入 -
最终答案:模型对原始用户查询的最终回答
-
-
React循环结束,最终答案返回给用户。
工具(Tools):通往外界的钥匙
扩展(Extensions)

-
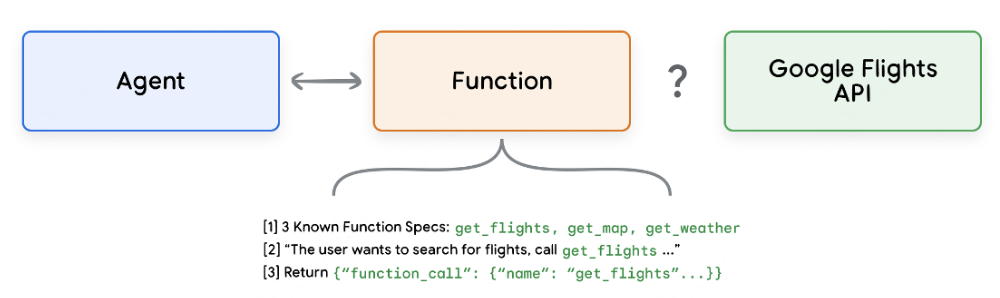
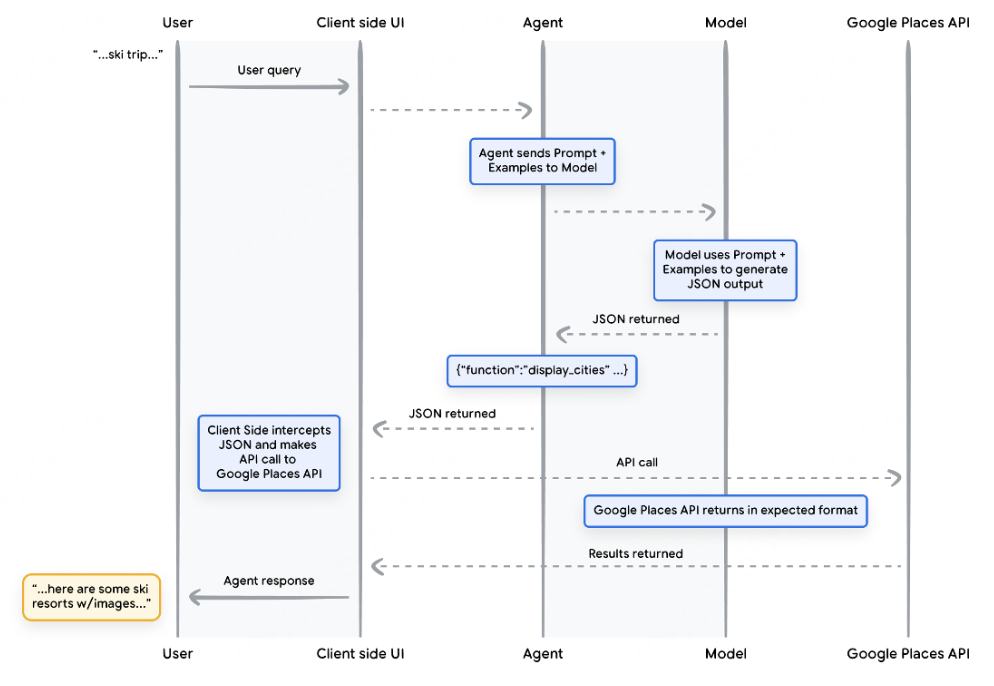
使用示例向Agent商展示如何使用API端点。 -
教给Agent需要成功调用API端点的哪些参数或参数。


-
需要在应用程序堆栈的另一层进行API调用,而不能在直接Agent架构流之外(例如中间件系统、前端框架等) -
安全或身份验证限制,这些限制阻止Agent直接调用API(例如,API未暴露到互联网上,或者无法通过Agent基础架构访问) -
时间或操作顺序约束,这些约束会阻止Agent在实时情况下调用API。(例如批处理作业、人机交互审核等) -
需要对Agent无法执行的API响应应用额外的数据转换逻辑。例如,考虑一个不提供限制返回结果数量过滤机制的API端点。在客户端使用函数为开发人员提供了更多机会来实现这些转换。 -
开发人员希望在不部署额外基础设施的情况下迭代Agent开发(即,函数调用可以像“API端点的占位符”一样工作)
-
美国科罗拉多州克雷斯特·布特 -
加拿大不列颠哥伦比亚省惠斯勒 -
瑞士策马特
-
您希望语言模型建议您在代码中可以使用的功能,但不想将凭证包含在您的代码中。因为函数调用不会运行该函数,因此您不需要在带有函数信息的代码中包括凭证。 -
您正在运行需要超过几秒钟的异步操作。这些场景与函数调用配合得很好,因为它是异步操作。 -
您想要在与产生函数调用及其参数的系统不同的设备上运行功能。
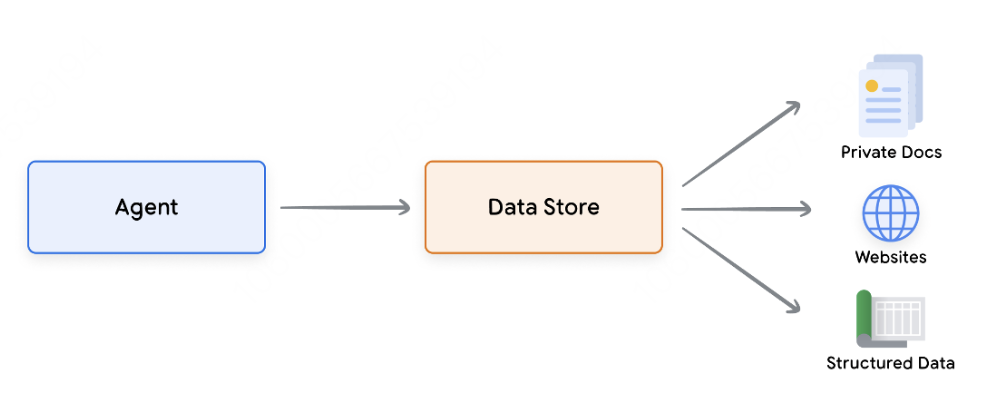
数据存储(Data stores)
-
网站内容 -
结构化数据,如PDF、Word文档、CSV、电子表格等格式。 -
未结构化的数据,如HTML、PDF、TXT等格式。
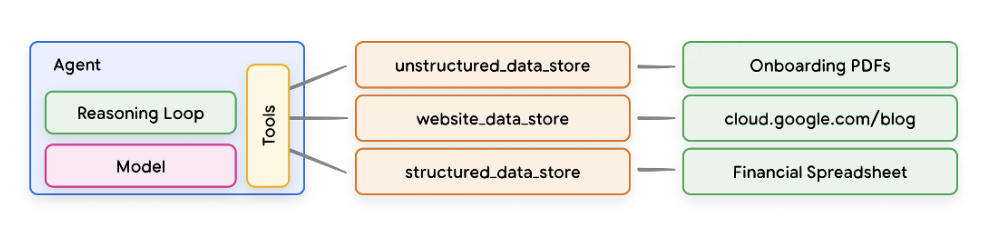
-
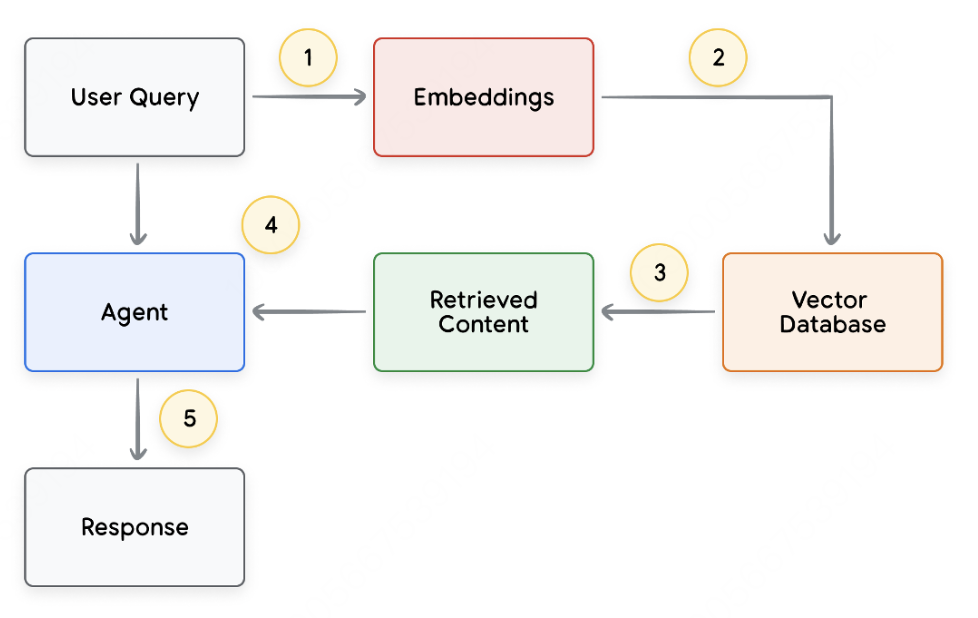
将用户查询发送到嵌入模型以生成查询的嵌入 -
接下来,查询嵌入向量将与矢量数据库中的内容使用匹配算法(如SCaNN)进行匹配。 -
匹配的内容以文本格式从向量数据库中检索并发送回Agent。 -
Agent程序接收用户查询和检索内容,然后制定响应或操作。 -
最终响应发送给用户。
工具总结(Tools recap)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
通过目标学习增强模型性能(Enhancing model performance with targeted learning)
- 在上下文中学习:这种方法在推理时提供了一个带有提示、工具和少量示例的通用模型,这使它能够“实时”学习如何以及何时使用这些工具来完成特定任务。ReAct 框架是自然语言中这种方法的一个例子。
- 基于检索的上下文学习:该技术通过从外部内存中检索最相关的信息、工具和关联示例,动态地将模型提示填充为最相关的信息。一个例子是Vertex AI扩展中的“示例存储”或前面提到过的基于RAG架构的数据存储。
- 精确调整学习:这种方法涉及在推理之前使用特定示例的大数据集对模型进行训练。这有助于模型了解何时以及如何在收到任何用户查询之前应用某些工具。
- 想象一下,一位厨师从客户那里收到了特定的食谱(提示)、一些关键食材(相关工具)和几道示例菜肴(少量示例)。基于这些有限的信息以及厨师对烹饪的一般知识,他们需要根据食谱和客户的偏好来确定如何“即兴”准备最接近的菜肴。这就是在上下文中学习。
- 现在让我们想象一下我们的厨师在一个厨房里,这个厨房有一个装满各种配料和食谱(示例和工具)的储藏室(外部数据存储)。现在厨师可以动态地从储藏室中选择配料和食谱,并更好地与客户的配方和偏好保持一致。这使厨师能够利用现有知识和新知识来创建更知情且精炼的菜肴。这是一种基于检索的上下文学习。
- 最后,让我们想象一下我们把厨师送回学校学习新的烹饪或一系列的烹饪(在特定示例的大数据集上进行预训练)。这使厨师能够以更深入的理解来应对未来的未见过的客户食谱。如果我们要让厨师精通于特定的烹饪知识领域,则这种方法是完美的。这是一种基于微调的学习方法。
使用 Vertex AI Agent的生产应用程序(Production applications with Vertex AI agents)